Sentiment analysis is a technique for evaluating the overall positivity, negativity, or neutrality of a body of text. It does this by scoring individual words based on whether they are positive or negative, and how strong a word it is in either direction. Positive words receive positive integers as a score, whereas negative words are represented by negative integers. The overall score for a body of text is the average of those numbers.
| Example Text | Sentiment Score |
|---|---|
| good | 3 |
| bad | -3 |
| mediocre | 0 |
| amazing | 4 |
| good and bad | 0 |
| amazing and bad | 1 |
Sentiment analysis isn’t perfect and there are plenty of examples where it will get things wrong, such as cases of sarcasm, context, or slang. For this reason, I’d be cautious using it for anything that requires rigour.
That being said, it’s an interesting technique for exploratory analysis. I’ve been looking for a good R package for sentiment analysis for quite some time, but more often than not they’re depreciated or don’t behave as expected. The Syuzhet package, however, seems to be what I was looking for.
Data
I decided to use an online transcript of the Leaders Debate before the UK’s 2015 general election. I thought it’d be interesting to compare the sentiment of the different debaters and see how they vary over the course of the event.
Firstly, load some packages and set up a few variables for graphing later.
library(rvest) # Web scraping
library(syuzhet) # Sentiment package
library(dplyr) # Wrangling
library(data.table) # Wrangling
library(zoo) # For dragging down non-NA values to NA columns
library(ggplot2) # Graphing
myTheme <- theme(legend.position="hidden",
panel.background = element_blank(),
panel.grid.major = element_line(colour = "grey"),
strip.background = element_rect(fill = "white"),
strip.text = element_text(face = "bold"))
colourList <- c("#999999", "#d50000", "#3F8428", "#008066", "#FDBB30", "#B3009D")Then I use the rvest package to scrape the transcript and dplyr and data.table to reshape the dataset into a usable format. Feel free to skip over this block if you’re only interested in the sentiment functions.
uri <- "http://webcache.googleusercontent.com/search?q=cache:yCrJUj1Pz-EJ:news-watch.co.uk/wp-content/uploads/2015/04/Transcript-of-BBC1-Opposition-Parties-Election-Debate.pdf+&cd=2&hl=en&ct=clnk&gl=uk"
# Read the html and split up
transcript <- read_html(uri) %>%
html_text() %>%
gsub(":", ":\n", .) %>%
strsplit(split = "\n")
# Remove some of the html header content
transcript <- transcript[[1]][-(1:52)]
# Remove empty lines and page numbers
transcript <- data.table(speaker = as.character(NA),
text = transcript,
stringsAsFactors = F) %>%
subset(text != "" & !(text %like% "Page "))
# Copy the speakers' names to their own column so that they can be dragged down.
transcript[text %in% c("DAVID DIMBLEBY:", "DD:"), speaker := "David Dimbleby"]
transcript[text %in% c("ED MILLIBAND:", "EM:"), speaker := "Ed Milliband"]
transcript[text %in% c("LEANNE WOOD:", "LW:", "LQ:"), speaker := "Leanne Wood"]
transcript[text %in% c("NIGEL FARAGE:", "NF:"), speaker := "Nigel Farage"]
transcript[text %in% c("NICOLA STURGEON:", "NS:"), speaker := "Nicola Sturgeon"]
transcript[text %in% c("NATALIE BENNETT:", "NB:"), speaker := "Natalie Bennett"]
transcript[text %in% c("EMILY MAITLIS:", "CHARLOTTE DENNIS:", "FIONA SWORD:",
"ANAIA SHANANE:", "LEON MATTHEW:",
"MICHAEL KENWORTHY:"), speaker := "Other"]
# Flag every row that contains unspoken dialogue as to be deleted.
transcript$toDelete <- F
transcript[!is.na(speaker), toDelete := T]
# Order the dialogue
transcript$order <- as.numeric(NA)
transcript[toDelete == T, order := as.numeric(seq(1, .N))]
# Drag down both the speaker and the order to NA columns
transcript$speaker <- na.locf(transcript$speaker)
transcript$order <- na.locf(transcript$order)
# Finally, delete the rows we're not interested in, group by order
# (including speaker to retain that column), and paste the text together.
transcript <- transcript %>%
subset(speaker != "Other" & toDelete == F) %>%
group_by(order, speaker) %>%
summarise(text = paste(text, collapse=" ")) %>%
ungroup()I tend to prefer dplyr over data.table, but you can’t really go wrong knowing both. The data.table package allows you to easily assign a new value to a subset of your data based on a condition, as was done with speaker names in the previous step.
So now we have the transcript in a more usable format, all we have to do to is call the get_sentiment() function on the text column, and store the returning numbers in a new column.
transcript$sentiment <- get_sentiment(transcript$text) %>% as.numeric()Analysis
Let’s look at the min, max, mean and median sentiment scores for each speaker.
transcript %>%
group_by(speaker) %>%
summarise(min = min(sentiment),
max = max(sentiment),
mean = round(mean(sentiment), 2),
median = median(sentiment),
times_spoken = n())| speaker | min | max | mean | median | times_spoken |
|---|---|---|---|---|---|
| David Dimbleby | -2 | 13 | 0.91 | 0.0 | 104 |
| Leanne Wood | -7 | 14 | 1.09 | 1.0 | 22 |
| Nigel Farage | -7 | 16 | 1.53 | 0.0 | 45 |
| Nicola Sturgeon | -2 | 14 | 3.32 | 2.5 | 28 |
| Natalie Bennett | -5 | 14 | 4.80 | 5.0 | 15 |
| Ed Milliband | -8 | 12 | -0.15 | 0.0 | 60 |
To find the most positive text, you can arrange by descending sentiment score and use head to return the first row:
transcript %>%
arrange(desc(sentiment)) %>%
select(speaker, sentiment, text) %>%
head(1)| speaker | sentiment | text |
|---|---|---|
| Nigel Farage | 16 | I think that the most important constitutional question this country faces is whether it is an independent self-governing nation or not. And it’s interesting to note that even the Nationalists believe in being members of the EU, therefore they don’t actually believe in true independence, we can’t be a an independent state and be part of the European Union. My view is, we should be outside of that. My view is we should govern ourselves, my view is we should be self-confident and reach out to the world. So, for me, for me if UKIP is in a position of influence in the next Parliament, we would want the British people to have a full, free and fair referendum so that they decide whether we have a trade deal with the EU or continued membership of the European Union. And it’s a mystery to me that the Labour Party, which used to be the party that actually believed that the EU would be bad for Britain now won’t even give the British people a referendum. I’m astonished by that. But that’s what I believe is the most important thing that UKIP in Parliament could fight for. (shout from audience, inaudible, and a smattering of applause) |
Alternatively, swap the head for tail to find the most negative speech.
transcript %>%
arrange(desc(sentiment)) %>%
select(speaker, sentiment, text) %>%
tail(1)| speaker | sentiment | text |
|---|---|---|
| Ed Milliband | -8 | I’m not going to have a European army, but let me explain - I think I’ve said that a number of times – er, look, let me explain the point about Europe, because Nigel raises it. Think about the problems that we have in the world, think about the issue of Russia where we need sanctions to remain in place and if necessary to be stepped up. It’s Europe and America working together. Think about the battle against Isis. Isis is a disgusting, evil organisation and we must give them no quarter and defeat them at home and abroad. But we’ve got to do it by cooperating across borders. And this is this fundamental point for us as a country. Look, we can’t, we’ve got to learn the lessons of the past. We can’t have Britain thinking it can solve the problems of the world on its own with the United States, that is the lesson of the 2003 Iraq war, but at the same time we can’t withdraw from the world because otherwise those problems will visit us at home. (applause) |
It’s worth pointing out that both the sentences with the lowest sentiment score and the highest sentiment score received applause from the audience. Therefore, just because text/speech has a low sentiment score doesn’t mean that it will not resonate with people. Text with negative sentiment scores simply use a larger proportion of (or stronger) negative words. This is another example as to why, while interesting, you should be cautious about the assumptions you make when using this technique.
Using the order column as a rough proxy for time, we can also look at how each speaker’s sentiment changes over the course of the debate.
transcript %>%
ggplot(aes(order, sentiment, color = speaker)) +
geom_line(size = 1) +
scale_color_manual(values = colourList) +
scale_x_continuous(name = "\nTime", breaks = NULL) +
scale_y_continuous(name = "Sentiment\n", breaks = seq(-15, 15, by=5)) +
facet_wrap(~ speaker) +
myTheme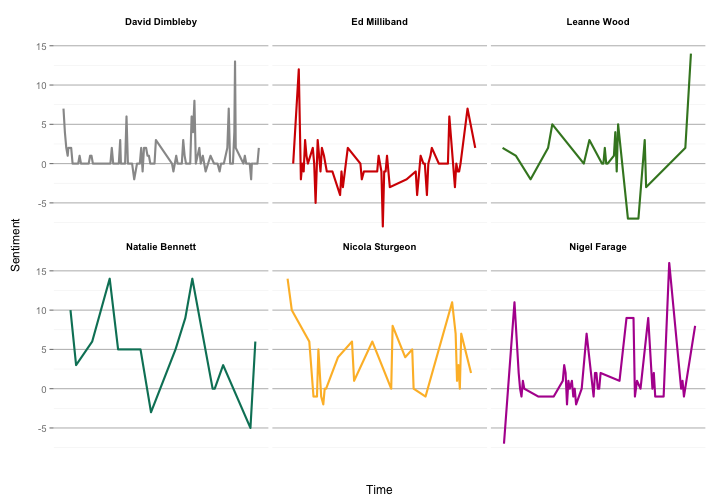
More Emotions
The Syuzhet package also supports the use of different Sentiment Analysis lexicons. The NRC method, for example, evaluates a body of text and returns positive values for eight different emotions (anger, anticipation, disgust, fear, joy, sadness, surprise, and trust), and two sentiments (negative and positive). You can compute these scores with the get_nrc_sentiment() function.
transcript <- cbind(transcript, get_nrc_sentiment(transcript$text))
transcript %>%
gather("emotion", "score", 5:14) %>%
ggplot(aes(order, score, color = speaker)) +
geom_line(size = 1) +
scale_color_manual(values = colourList) +
scale_x_continuous(name = "\nTime", breaks = NULL) +
scale_y_continuous(name = "Sentiment\n", breaks = seq(0, 15, by=5)) +
facet_grid(speaker ~ emotion) +
myTheme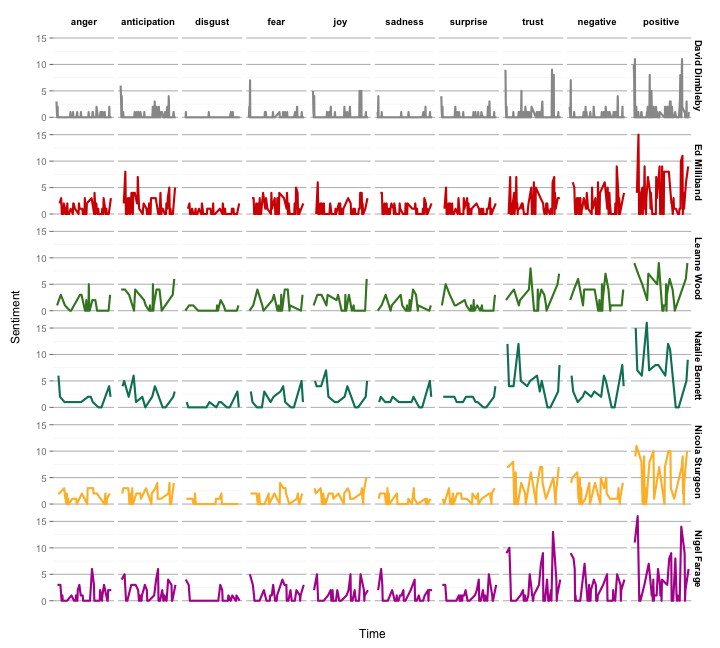
As the lexicons being used are different, it may be the case that the scores from the first method (afinn) and the scores from the second method (NRC) deviate from each other.
Summary
The Syuzhet package is an easy way to get up and running with Sentiment Analysis on R. The different lexicons highlight that there is no one universally recognised technique, and no one technique is perfect. It can, however, lead to some interesting exploratory analysis, especially when combined with web scraping. I think it would be interesting to explore sentiment analysis as one input into a larger predictive model, and hopefully I’ll get a chance to explore this over the next few weeks.